PROFESSIONAL-CLOUD-DEVELOPER Online Practice Questions and Answers
You are a developer at a large organization Your team uses Git for source code management (SCM). You want to ensure that your team follows Google-recommended best practices to manage code to drive higher rates of software delivery. Which SCM process should your team use?
A. Each developer commits their code to the main branch before each product release, conducts testing, and rolls back if integration issues are detected.
B. Each group of developers copies the repository, commits their changes to their repository, and merges their code into the main repository before each product release.
C. Each developer creates a branch for their own work, commits their changes to their branch, and merges their code into the main branch daily.
D. Each group of developers creates a feature branch from the main branch for their work, commits their changes to their branch, and merges their code into the main branch after the change advisory board approves it.
You are developing an application that consists of several microservices running in a Google Kubernetes Engine cluster. One microservice needs to connect to a third-party database running on-premises. You need to store credentials to the database and ensure that these credentials can be rotated while following security best practices. What should you do?
A. Store the credentials in a sidecar container proxy, and use it to connect to the third-party database.
B. Configure a service mesh to allow or restrict traffic from the Pods in your microservice to the database.
C. Store the credentials in an encrypted volume mount, and associate a Persistent Volume Claim with the client Pod.
D. Store the credentials as a Kubernetes Secret, and use the Cloud Key Management Service plugin to handle encryption and decryption.
Your organization has recently begun an initiative to replatform their legacy applications onto Google Kubernetes Engine. You need to decompose a monolithic application into microservices. Multiple instances have read and write access to a configuration file, which is stored on a shared file system. You want to minimize the effort required to manage this transition, and you want to avoid rewriting the application code. What should you do?
A. Create a new Cloud Storage bucket, and mount it via FUSE in the container.
B. Create a new persistent disk, and mount the volume as a shared PersistentVolume.
C. Create a new Filestore instance, and mount the volume as an NFS PersistentVolume.
D. Create a new ConfigMap and volumeMount to store the contents of the configuration file.
Your service adds text to images that it reads from Cloud Storage. During busy times of the year, requests to
Cloud Storage fail with an HTTP 429 "Too Many Requests" status code.
How should you handle this error?
A. Add a cache-control header to the objects.
B. Request a quota increase from the GCP Console.
C. Retry the request with a truncated exponential backoff strategy.
D. Change the storage class of the Cloud Storage bucket to Multi-regional.
This architectural diagram depicts a system that streams data from thousands of devices. You want to ingest data into a pipeline, store the data, and analyze the data using SQL statements. Which Google Cloud services should you use for steps 1, 2, 3, and 4?
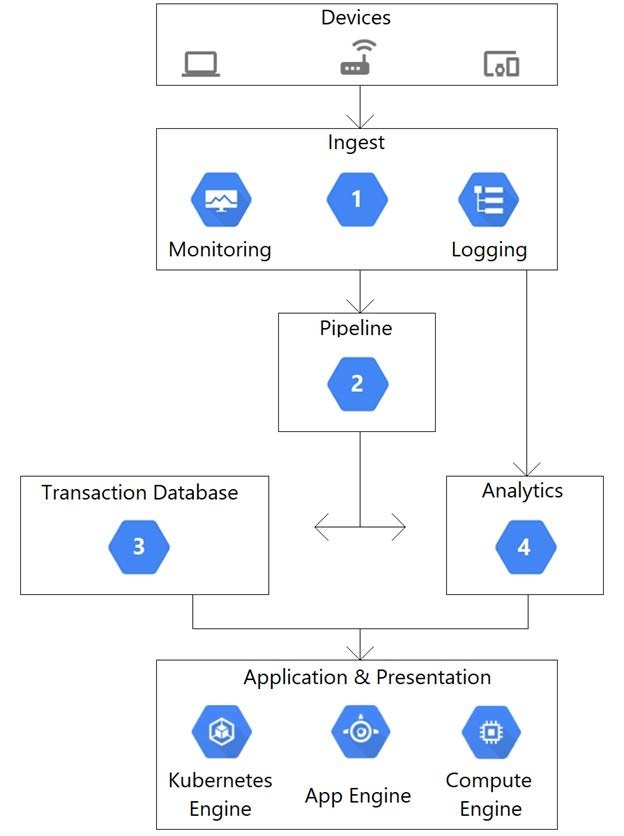
A. 1) App Engine 2) Pub/Sub 3) BigQuery 4) Firestore
B. 1) Dataflow 2) Pub/Sub 3) Firestore 4) BigQuery
C. 1) Pub/Sub 2) Dataflow 3) BigQuery 4) Firestore
D. 1) Pub/Sub 2) Dataflow 3) Firestore 4) BigQuery
You are a developer working with the CI/CD team to troubleshoot a new feature that your team introduced. The CI/CD team used HashiCorp Packer to create a new Compute Engine image from your development branch. The image was successfully built, but is not booting up. You need to investigate the issue with the CI/CD team. What should you do?
A. Create a new feature branch, and ask the build team to rebuild the image.
B. Shut down the deployed virtual machine, export the disk, and then mount the disk locally to access the boot logs.
C. Install Packer locally, build the Compute Engine image locally, and then run it in your personal Google Cloud project.
D. Check Compute Engine OS logs using the serial port, and check the Cloud Logging logs to confirm access to the serial port.
You are deploying your application to a Compute Engine virtual machine instance. Your application is
configured to write its log files to disk. You want to view the logs in Stackdriver Logging without changing the
application code.
What should you do?
A. Install the Stackdriver Logging Agent and configure it to send the application logs.
B. Use a Stackdriver Logging Library to log directly from the application to Stackdriver Logging.
C. Provide the log file folder path in the metadata of the instance to configure it to send the application logs.
D. Change the application to log to /var/log so that its logs are automatically sent to Stackdriver Logging.
You deployed a new application to Google Kubernetes Engine and are experiencing some performance degradation. Your logs are being written to Cloud Logging, and you are using a Prometheus sidecar model for capturing metrics. You need to correlate the metrics and data from the logs to troubleshoot the performance issue and send real-time alerts while minimizing costs. What should you do?
A. Create custom metrics from the Cloud Logging logs, and use Prometheus to import the results using the Cloud Monitoring REST API.
B. Export the Cloud Logging logs and the Prometheus metrics to Cloud Bigtable. Run a query to join the results, and analyze in Google Data Studio.
C. Export the Cloud Logging logs and stream the Prometheus metrics to BigQuery. Run a recurring query to join the results, and send notifications using Cloud Tasks.
D. Export the Prometheus metrics and use Cloud Monitoring to view them as external metrics. Configure Cloud Monitoring to create log-based metrics from the logs, and correlate them with the Prometheus data.
You are designing a schema for a table that will be moved from MySQL to Cloud Bigtable. The MySQL table is as follows:

How should you design a row key for Cloud Bigtable for this table?
A. Set Account_id as a key.
B. Set Account_id_Event_timestamp as a key.
C. Set Event_timestamp_Account_id as a key.
D. Set Event_timestamp as a key.
You are developing an event-driven application. You have created a topic to receive messages sent to Pub/Sub. You want those messages to be processed in real time. You need the application to be independent from any other system and only incur compute costs when new messages arrive. You want to configure the simplest and most efficient architecture What should you do?
A. Deploy your code on Cloud Functions. Use a Pub/Sub trigger to invoke the Cloud Function. Use the Pub/Sub API to create a pull subscription to the Pub/Sub topic and read messages from it.
B. Deploy your code on Cloud Functions. Use a Pub/Sub trigger to handle new messages in the topic.
C. Deploy the application on Google Kubernetes Engine. Use the Pub/Sub API to create a pull subscription to the Pub/Sub topic and read messages from it
D. Deploy the application on Compute Engine. Use a Pub/Sub push subscription to process new messages in the topic.

Home | Contact Us | About Us | FAQ | Guarantee & Policy | Privacy & Policy | Terms & Conditions | How to buy
Copyright © 2026 pass4itsure.com. All Rights Reserved