DATABRICKS-CERTIFIED-PROFESSIONAL-DATA-SCIENTIST Online Practice Questions and Answers
Which of the following is not a correct application for the Classification?
A. credit scoring
B. tumor detection
C. image recognition
D. drug discovery
RMSE is a useful metric for evaluating which types of models?
A. Logistic regression
B. Naive Bayes classifier
C. Linear regression
D. All of the above
Digit recognition, is an example of.....
A. Classification
B. Clustering
C. Unsupervised learning
D. None of the above
A. It creates the smaller models
B. It requires the lesser memory to store the coefficients for the model
C. It reduces the non-significant features e.g. punctuations
D. Noisy features are removed
In which of the following scenario we can use naTve Bayes theorem for classification
A. Classify whether a given person is a male or a female based on the measured features. The features include height, weight and foot size.
B. To classify whether an email is spam or not spam
C. To identify whether a fruit is an orange or not based on features like diameter, color and shape
You have data of 10.000 people who make the purchasing from a specific grocery store. You also have their income detail in the data. You have created 5 clusters using this data. But in one of the cluster you see that only 30 people are falling as below 30, 2400, 2600, 2700, 2270 etc."
What would you do in this case?
A. You will be increasing number of clusters.
B. You will be decreasing the number of clusters.
C. You will remove that 30 people from dataset
D. You will be multiplying standard deviation with the 100
Suppose that we are interested in the factors that influence whether a political candidate wins an election. The outcome (response) variable is binary (0/1); win or lose. The predictor variables of interest are the amount of money spent on the campaign, the amount of time spent campaigning negatively and whether or not the candidate is an incumbent.
Above is an example of:
A. Linear Regression
B. Logistic Regression
C. Recommendation system
D. Maximum likelihood estimation
E. Hierarchical linear models
Under which circumstance do you need to implement N-fold cross-validation after creating a regression model?
A. The data is unformatted.
B. There is not enough data to create a test set.
C. There are missing values in the data.
D. There are categorical variables in the model.
Suppose that the probability that a pedestrian will be tul by a car while crossing the toad at a pedestrian crossing without paying attention to the traffic light is lo be computed. Let H be a discrete random variable taking one value from (Hit. Not Hit). Let L be a discrete random variable taking one value from (Red. Yellow. Green).
Realistically, H will be dependent on L That is, P(H = Hit) and P(H = Not Hit) will take different values depending on whether L is red, yellow or green. A person is. for example, far more likely to be hit by a car when trying to cross while Hie lights for cross traffic are green than if they are red In other words, for any given possible pair of values for Hand L. one must consider the joint probability distribution of H and L to find the probability* of that pair of events occurring together if Hie pedestrian ignores the state of the light
Here is a table showing the conditional probabilities of being bit. defending on ibe stale of the lights (Note that the columns in this table must add up to 1 because the probability of being hit oi not hit is 1 regardless of the stale of the light.)
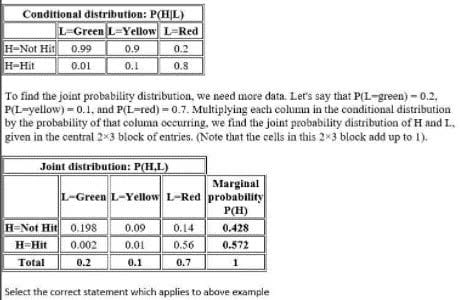
A. The marginal probability P(H=Hit) is the sum along the H=Hit row of this joint distribution table, as this is the probability of being hit when the lights are red OR yellow OR green.
B. marginal probability that P(H=Not Hit) is the sum of the H=Not Hit row
C. marginal probability that P(H=Not Hit) is the sum of the H= Hit row
Select the correct statement which applies to Supervised learning
A. We asks the machine to learn from our data when we specify a target variable.
B. Lesser machine's task to only divining some pattern from the input data to get the target variable
C. Instead of telling the machine Predict Y for our data X, we're asking What can you tell me about X?

Home | Contact Us | About Us | FAQ | Guarantee & Policy | Privacy & Policy | Terms & Conditions | How to buy
Copyright © 2026 pass4itsure.com. All Rights Reserved