AD0-E600 Online Practice Questions and Answers
There are two existing entities in the Real-time Customer Profile store: one profile record and one event.

Both the event schema and profile schema have "email" as the primary identity. The _id is used to identify unique events.
Later, a data engineer ingests one additional profile fragment and another event:
Profile: ("email": "john@example.com*. "favBrand': "Adobe")
Event: {`'_id": '5000". "email": "john@example.com". "purchase": "Photoshop 2021")
What will the profile attributes and event look like when doing a profile lookupforjohn@example.com?

A. Option A
B. Option B
C. Option C
D. Option D
A data engineer is required to partially ingest data via a Source Connector. Which three source connectors are permitted for this task? (Choose three.)
A. FTP/SFTP
B. HTTP API
C. Adobe Analytics
D. Azure Blob Storage
E. Microsoft Dynamics
F. Web SDK
A marketer recently set up an Amazon S3 cloud storage destination. The last successful flow for the destination exported 12 million records. in the Amazon S3 bucket, how will the export be presented to the marketer?
A. 3 CSV files in the format of: filename.csv {containing 5 million records) filename_2.c$v (containing 5 million records) ftlename_3.csv (containing 2 million records)
B. 1 CSV file in the format of: filename.csv (containing 12 million records)
C. 2 CSV files in the format of filename.csv (containing 6 million records) filename_2.csv (containing 6 million records)
D. 3 JSON files in the format of: filenamejson (containing 5 million records) filename_2json (containing 5 million records) filename.3json (containing 2 million records)
A data engineer is ingesting time-series data in CSV format from a CRM system. The source data contains a "subscription" field that contains what level of subscription the customer has purchased.
The data is ingested into a target field called "subscriptionLevel". which is an enum field that accepts the following values: "Lite*. "Standard", and "Pro''.
The data engineer knows that the CSV files contain some rows that do not conform to the above enum. Instead of rejecting those rows, the data engineer wants to transform non- conforming fields to "Standard".
Which mapping function(s) will accomplish this?
A. iif(subscription.equals("Lite") andandsubscriptiorvequ3ls("Standard") andand sub$ctiption.eqoals("Pro"). subscription. el$e("5tandard"))
B. iif(subscription.noiEquals(*Lite" || "Standard" || "Pro"), subscription, subscription, replacestrf "Standard"))
C. iif(subscription.notEquals("Lite") || subscription.notEqualsl "Standard") || subscription.notEquatsCPro'). 'Standard', subscription)
D. iif(subscription.equals("Lite") || subscription.equals("Standard") || subscriptionequalsfPro"). subscription. "Standard")
A marketer wants 10 create a segment that qualities profiles from all datasets that are enabled for profile. The use case for the segment is for activation to advertising destinations. Based on the options for ID stitching and merge method respectively, which type of merge policy is appropriate for this use case?
A. ID stitching: None Merge method: Dataset precedence
B. ID stitching: None Merge method: Timestamp ordered
C. ID stitching: Private graph Merge method: Dataset precedence
D. ID stitching: Private graph Merge method: Timestamp ordered
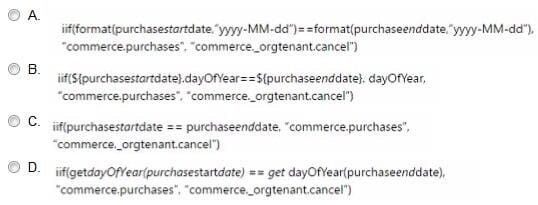
A data engineer is ingesting the transactional information from an ecommerce platform through a daily feed. In AEP, one Experience Event-based schema will collect the purchase events from this feed.
The eventType field of the schema must be populated with "commerce.purchases' if in a CSV record in which the column 'pure ha sesf arid ate' and 'purchaseenddate" happen on the same day, If the "purchasee/irfdate" is set to a later date,
the eventType should be *commerce._orgtenant.cancer.
Both dates follow the same format "yyyy-MM-dd'T'HH:mm:ss.SSS'Z~. and the "purchaseenddate' is always populated.
How should the data engineer create a Calculated Field that can be used to populate the eventType according to the required logic?
A. Option A
B. Option B
C. Option C
D. Option D
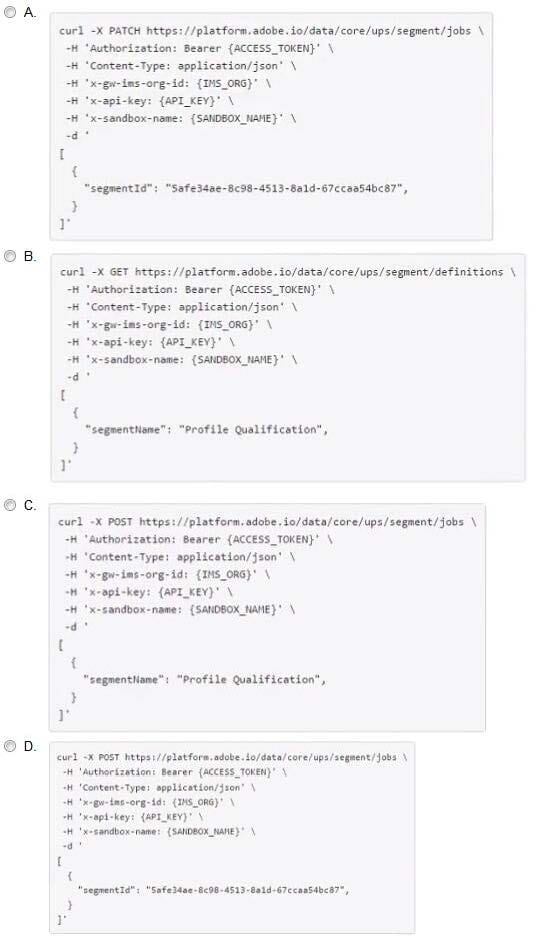
A daily scheduled segmentation job has already run and completed. However, the data engineer recently created a new segment.
Segment Name: Profile Qualification
Segment ID: Safe34ae-Sc98-4Sl3-8a1d-67ccaaS4bc87
The data engineer wants to evaluate this segment via API.
How should the data engineer proceed?
A. Option A
B. Option B
C. Option C
D. Option D
A national workout studio chain deploys a new booking system and can now track when a customer puns to 90 into a training session. The studio chain wants to use that information to power their email campaigns. The event data that is collected when a customer books a session does not include information like the Sport category or the level of physical condition the customers should have. That information is stored in a different dataset. The studio chain is using AEP and will have access to the following databases;
BOOK A TRAINING SESSION EVENT DATABASE: Time stamp Session ID Member ID TRAINING SESSION METADATA DATABASE:
Session ID
Sport category
Required physical condition
The data architects needs to configure the AEP XDM schemas to be able to build a relationship between the two databases so that the Sport category and the Required physical condition can be used in the AEP segment builder.
How should the data architect configure the AEP XDM to meet these requirements?
A. Createone schema (schema A) using the Experience Event Schema as the XDM class for the Book a Training Session Event Create out schema (schema B> using individual Profile as the XDM class for the Training Session Metadata Usethe Member ID as the primary identity of the schema A Use the Session ID as a relationship fieldon schema A Use the Session ID as the primary identity of theschema B Enable schema A for profile
B. Create one schema (schema A) using the Experience Event Schema as the XDM class 'or the Book a Training Session Event Create one schema (schema B) using a custom XDM class for the Training Session Metadata Use the Member ID as the primary identity of the schema A Use the Session ID as a relationship field on schema A Use the Session ID as the primary identity of the schema B Enable both schemas for profile Create one schema (schema A) using the Experience Event Schema as the XDM class for the Book a Training Session Event
C. Create one schema (schema B) using a custom XDM class for the Training Session Metadata Use the Member ID as the primary identity of the schema A Use the Session ID as the secondary identity of the schema A Use the Session ID as the primary identity of the schema B Enable both schemas for profile
D. Create one schema using Experience Event as the XDM class Create Field Groups to include all the attributes from both the Book a Training Session Event and the Training Session Metadata Use the Member ID as the primary identity of that schema Use the Session ID as a secondary identity of that schema Configure one dataflow per database but use the same dataset to store the info
A national workout studio chain is introducing a new Family discount program. They have already deployed AEP with the following data model:
Members Schema (Individual Profile Based): Primary ID: Member ID Secondary IDs: Email Hash. Phone Hash Training Sessions Management (Experience Event): Primary ID: Member ID Secondary IDs: ECID Subscription Management (Experience Event): Primary ID: Email Hash Secondary IDs: ECID
The workout studio wants to be able to use all of this information together with the family details to segment For example, they want totarget families where one familymember trams daily or one family member has the yearly subscription plan.
To start collecting Family information, the workout studio creates a form where the members can create a Family account and associate the different members to it The form will collect a list of Member IDs and generate a Family ID. A data architect will design a new schema to store the Family information.
Which identities should be used in the schema(s) to collect this form information?
A. The Family ID should be defined as a cross-device identity and set up as a secondary identity. The Member IDs should be used as primary identities.
B. The Family ID should be defined as a cross-device identity and set up as the primary identity. The Member IDs should be used as secondary identities.
C. The Family ID should be defined as a non-people identity and set up as a primary identity. The Member ID should be set up as a relationship with the Members Schema.
D. The Family ID should be defined as a non-people identity and set up as the primary identity. The Family ID should also be an attribute of the Members Schema and set up as a relationship.
A data engineer is ingesting website data via CSV that represents a future hotel reservation.

Each field is mapped to the corresponding target field below:
"fullName": "string", 'crmld": "string", "email": "string", "swyDate": "dateTime", "_id": "string"
Upon mapping the data, the mapping step fails with an error.
What is the possible cause of this error?
A. _id field is passed in manually instead of autogenerated.
B. CRM ID is an integer when the target field is a string.
C. The source datelime format is incompatible with XDM.
D. The default timestamp field is required upon ingestion.

Home | Contact Us | About Us | FAQ | Guarantee & Policy | Privacy & Policy | Terms & Conditions | How to buy
Copyright © 2026 pass4itsure.com. All Rights Reserved