DS-200 Online Practice Questions and Answers
Why should stop an interactive machine learning algorithm as soon as the performance of the model on a test set stops improving?
A. To avoid the need for cross-validating the model
B. To prevent overfitting
C. To increase the VC (VAPNIK-Chervonenkis) dimension for the model
D. To keep the number of terms in the model as possible
E. To maintain the highest VC (Vapnik-Chervonenkis) dimension for the model
There are 20 patients with acute lymphoblastic leukemia (ALL) and 32 patients with acute myeloid leukemia (AML), both variants of a blood cancer.
The makeup of the groups as follows:
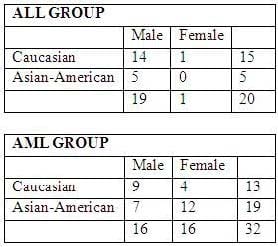
Each individual has an expression value for each of 10000 different genes. The expression value for each gene is a continuous value between -1 and 1.
With which type of plot can you encode the most amount of the data visually?
You choose to perform agglomerative hierarchical clustering on the 10,000 features. How much RAM do you need to hold the distance Matrix, assuming each distance value is 64-bit double?
A. ~ 800 MB
B. ~ 400 MB
C. ~ 160 KB
D. ~ 4 MB
In what way can Hadoop be used to improve the performance of LIoyd's algorithm for k-means clustering on large data sets?
A. Parallelizing the centroid computations to improve numerical stability
B. Distributing the updates of the cluster centroids
C. Reducing the number of iterations required for the centroids to converge
D. Mapping the input data into a non-Euclidean metric space
How can the naiveté of the naive Bayes classifier be advantageous?
A. It does not require you to make strong assumptions about the data because it is a non- parametric
B. It significantly reduces the size of the parameter space, thus reducing the risk of over fitting
C. It allows you to reduce bias with no tradeoff in variance
D. It guarantees convergence of the estimator
What are two defining features of RMSE (root-mean square error or root-mean-square deviation)?
A. It is sensitive to outliers
B. It is the mean value of recommendations of the K-equal partitions in the input data
C. It is the square of the median value of the error where error is the difference between predicted rating and actual ratings
D. It is appropriate for numeric data
E. It considers the order of recommendations
Consider the following sample from a distribution that contains a continuous X and label Y that is either A or B:
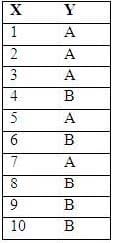
Which is the best cut point for X if you want to discretize these values into two buckets in a way that minimizes the sum of chi-square values?
A. X 8
B. X 6
C. X 5
D. X 4
E. X 2
You have a large file of N records (one per line), and want to randomly sample 10% them. You have two
functions that are perfect random number generators (through they are a bit slow):
Random_uniform () generates a uniformly distributed number in the interval [0, 1] random_permotation (M)
generates a random permutation of the number O through M -1.
Below are three different functions that implement the sampling.
Method A
For line in file: If random_uniform () < 0.1; Print line
Method B
i = 0
for line in file:
if i % 10 = = 0;
print line
i += 1
Method C
idxs = random_permotation (N) [: (N/10)]
i = 0
for line in file:
if i in idxs:
print line
i +=1
Which method might introduce unexpected correlations?
A. Method A
B. Method B
C. Method C
You want to build a classification model to identify spam comments on a blog. You decide to use the words in the comment text as inputs to your model. Which criteria should you use when deciding which words to use as features in order to contribute to making the correct classification decision?
A. Choose words for your sample that are most correlated with the Spam label
B. Choose words for your sample that occur most frequently in the text
C. Choose words, for your sample that have the largest mutual information with the spam label
D. Choose words for your sample that are least correlated with the spam label
Given the following sample of numbers from a distribution:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89 What are the five numbers that summarize this distribution (the five number summary of sample percentiles)?
A. 1, 3, 8, 34, 89
B. 1, 4, 13, 34, 89
C. 1, 1.5, 5, 24.5, 89
D. 1, 2.5, 8, 27.5, 89
Given the following sample of numbers from a distribution:
1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89
How do high-level languages like Apache Hive and Apache Pig efficiently calculate approximately percentiles for a distribution?
A. They sort all of the input samples and the lookup the samples for each percentile
B. They maintain index of input data as it is loaded into HDFS and load them into memory
C. They use pivots to assign each observations to the reducer that calculate each percentile
D. They assign sample observations to buckets and then aggregate the buckets to compute the approximations

Home | Contact Us | About Us | FAQ | Guarantee & Policy | Privacy & Policy | Terms & Conditions | How to buy
Copyright © 2025 pass4itsure.com. All Rights Reserved